
2.3.9 Get rid of duplicate content and What is rel = "canonical"?

In the first place I'd like to warn you that this chapter is gonna be probably the hardest to read as here I'll lift the veil over the technical SEO aspects. But don't rush to skip it. Most useful and important things in our life don't come easy. And I urge you to read this chapter as it'll not only give you an insight into the issues faced by almost every SEO, but also tell you how to solve them. I'm sure you'll thank me for it later.
You'll also need your webmaster's help to implement what I describe here (if necessary). But anyway, you need to understand what your webmaster is doing, so let's start:)
What is duplicate content?
So, duplicate content refers to blocks of content, that either completely or partially match other content. There are two types of duplicates: internal (which appear within your website) and external (which appears across different domains).
As you can imagine, Google puts a huge lot of resources into the non–stop indexing of the Web. No wonder, it wants to minimize these amounts. That's why Google once introduced a thing called "supplemental" index. The pages contained within it, are like 2–nd–class citizens, from Google's and an SEO's perspective, and have no ranking ability.
The supplemental results are hidden behind this warning at the bottom of a Google SERP:
 "Omitted" results warning
"Omitted" results warning
The point is: if your pages appear in the supplemental index being treated as unimportant or duplicate, they are not viewed and clicked by users. Of course, in many cases, they really are duplicates or have very little search value, but that's not always the case. That's why it's you and only you who is responsible for the right pages to appear in the main index.
Besides, if you have content that is duplicated, Google may rank the wrong page, which can be more authoritative according to its algorithm, but not the one you would expect to rank. If that happens, the wrong URLs will show up in the search results and that's not what we aim for, right?
How to diagnose duplicate content?
As we all know, prevention is better than cure. And this is relevant for SEO activities as well. Instead of eliminating duplicate pages you'd rather evaluate your website structure first, to make sure there are no accidentally generated pages with no value to users. That's why the first critical step towards a healthy website structure is to systematically navigate your site to find where duplicates are being created.
There are different tools which may assist you, including "This–Which–Must–Not–Be–Named–Yet". But right now I'd like to describe those which are free and easy–to–use.
- Google Webmaster Tools
In Google Webmaster Tools you can get a list of duplicate TITLE tags and Meta Descriptions Google has crawled. In your account, go to "Optimization" > "HTML Improvements" and you'll see a table like this:
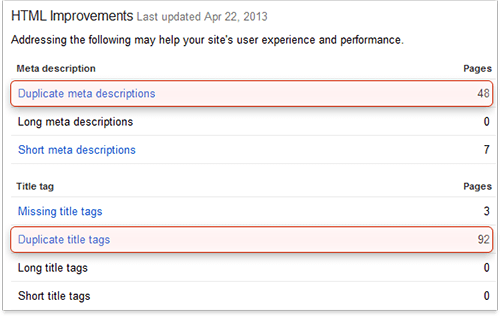 HTML improvements module in Google Webmaster Tools
HTML improvements module in Google Webmaster Tools
- Google's site: operator
When you already have a clue of where you might be running into trouble and need to take a deeper dive, use Google's "site:" operator.
I hope you remember this operator, as with its help we've already checked the number of indexed pages. Now, to detect if there are duplicates of a certain page, combine the "site:" operator with regular search text (such as blocks of repeated content). Just include a piece of text you want to scan in quotes:
I'd also like to mention that leaving off a site: operator and just searching for a unique block of content in quotes is a cheap and easy way to find out if your content is scraped. Try it yourself!
- Copyscape (http://www.copyscape.com/)
This is another free and easy–to–use tool. However, this one is good for the detection of external duplicates and lousy website owners scraping your content, not for the duplicates within your website.
Go to Copyscape.com and enter a URL of a page you suspect can be scraped. As a result, you get a list of pages with similar content, and if you click on any of them, you are directed to a page, where you can see exactly how much and what text was copied from your webpage.
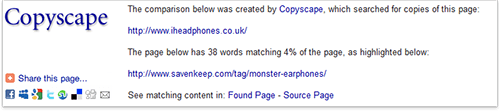 Copyscape.com check
Copyscape.com check
DO IT NOW! Perform the checks described above to make sure your website content is not being scraped.
How to deal with duplicate content?
Now, as you already know how to detect a problem, you may be wondering how to solve it. Below are the most popular causes of duplicate content and ways to eliminate it. Stay tuned!
Take external duplicates out of the way
Let's start with external duplicates. Quite common are situations when a webmaster sets up a new website and simply forgets to delete an old one or block it from indexing. No need to mention, the content on both websites is similar, and both of them get indexed and ranked.
Another common scenario occurs when affiliates or resellers copy your content without asking.
If you syndicate large pieces of content to other sites, you are also at risk. Direct from Google guidelines:
"If you syndicate your content on other sites, Google will always show the version we think is most appropriate for users in each given search, which may or may not be the version you'd prefer."
Solution:
a) If you need to provide a description of your website, don't copy it from your own homepage. Instead, spend a couple of minutes writing a unique one.
b) If you own several domains with similar content, you can create a cross–domain canonical tag. (Detailed explanation can be found at http://googlewebmastercentral.blogspot.com/2009/12/handling–legitimate–cross–domain.html). Basically, you need to choose which URL is going to be the source, and redirect to that.
c) If you don't own the domains, then you need to work with the webmasters to fix that problem, educate your affiliates and mention your site as the original source if you decide to syndicate part of its contents.
Handle internal duplicates

Now it's high time we take a look at the internal duplicates, i.e. the ones within your website. They are often triggered by the settings of the content management system or a complex website structure.
Now I'll describe most common issues, due to which duplicate content may appear on your website and, of course, how to handle them.
- 1) Different URLs lead to the same content (duplicate paths). Here's an example.
On Macy's website, I can go to the Quilts & Bedspreads page:
- directly (to http://www1.macys.com/shop/bed–bath/quilts–bedspreads?id=22748),
OR I can take different routes from the homepage: - I can go to Homepage >>Bed& Bath >> Quilts & Bedspreads, with the following URL being generated:
http://www1.macys.com/shop/bed–bath/quilts–bedspreads?id=22748&edge=hybrid&cm_sp=us_catsplash_bed–%26–bath–_–row6–_–quilts–%26–bedspreads,
OR - I can go to Homepage >> For the Home >> Bed & Bath >> Bedding >> Quilts & Bedspreads, and the URL will be: http://www1.macys.com/shop/bed–bath/quilts–bedspreads?id=22748&edge=hybrid
As you can imagine, when a search bot comes to your website and sees three pages with similar content, it's a bit lost and can't make up his mind, which page should go to the main index and rank. And you need to help him out.
Solution: The solution is already successfully implemented on the Macy's website. If you look into the code of each page, you'll see the following tag in the head element:

This is a canonical tag, which sets the main cleanest URL http://www1.macys.com/shop/bed–bath/quilts–bedspreads?id=22748 as canonical.
Adding this tag lets you identify pages with identical content and say to Google: "Of all these pages with identical content, this page is the most useful. Please prioritize it in search results." As a result, the SEO value each of these URLs might have is funneled down to one single URL that should be displayed in the search results.
DO IT NOW! If you want to specify a canonical page, add a <link> element with the attribute rel="canonical" to the <head> section of the non–canonical version of the page. If this sounds confusing, just tell your webmaster to implement this.
You can also find more information about the canonical tag at http://support.google.com/webmasters/bin/answer.py?hl=en&answer=139394
- 2) One and the same page is available at several URLs.
For example, a page may be available at: http://www.example.com/page/, http://example.com/page/ (non–www version), http://www.example.com/page (without slash) and http://www.example.com/page/index.html.
These examples may refer to any website page, but there's a typical concern, associated with the homepage. There are cases when the root domain and the actual homepage document name get indexed, resulting in the homepage being available at http://www.example.com and http://www.example.com/index.html
Solution: First of all, be consistent with your internal paths. If you want the root version of the URL to be the main one, but then link to /index.html in your navigation, you're sending mixed signals to Google every time the crawler visits your site.
Generally, these problems are solved with a 301–redirect (by redirecting the second version of the page to the main one). If you use a 301 redirect and not another variation, you may be sure the link juice form the redirected page is passed to the chosen one.
Detailed information about 301 redirects you'll find at
http://support.google.com/webmasters/bin/answer.py?hl=en&answer=93633.
- 3) Some websites (especially online shops) tag each new visitor with a tracking parameter. On occasion, it ends up in the URL and gets indexed, creating something like http://www.example.com/?session=123. This can easily add 1000s of duplicate pages to your index.
Solution: The best option (if possible on your site) is to remove the session ID from the URL altogether and store it in a cookie.
A cookie is a small piece of data sent from a website and stored in a user's web browser while a user is browsing a website. When the user browses the same website in the future, the data stored in the cookie can be retrieved by the website to notify the website of the user's previous activity — Wikipedia.
If that's not possible, try implementing the canonical tag on all these session pages.
Additionally, you can use Google Webmaster Tools to specify URL parameters that you want Google to ignore. If you click on "Configuration" > "URL parameters", you'll get a list something like this:
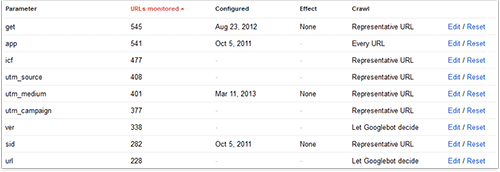 List of parameters in Google Webmaster Tools
List of parameters in Google Webmaster Tools
This list shows URL parameters that Google has detected and their settings. If you click on "Edit", you'll get the following options:
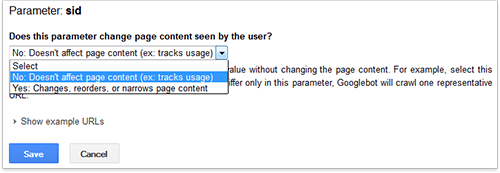 Editing parameter settings
Editing parameter settings
There are several options in the dropdown menu. "Yes" means the parameter is important and should be indexed, while "No" means the parameter indicates a duplicate. As you see, you hold all the cards!
- 4) If you are a proud owner of an online shop, your website probably features search filters (price, color, features, etc.), like in the example below:
Search filter
And generated search filter URLs look similar to:
http://www.myntra.com/men–shorts?nav_id=395#!sizes=m|colour=black|Length_article_attr=mid%20length
Pay no mind to the shorts themselves, as I was just searching for a gift for Andy.
But if you take a closer look at the generated URL, you'll see that I'm looking for black shorts (colour= parameter) of size M (sizes=) and of medium length (Length_article_attr=). Just like that, alongside learning how search filters operate, you learn more about my son's clothing choices
Solution: In most cases, it's best to not index the filters, by adding a Meta Noindex tag to pages with questionable parameters. In its simplest form, the tag looks something like this:

Meta robots tag
This line tells search bots not to index this particular page or follow links on it. However, in the case with search filters I'd recommend making it "NOINDEX, FOLLOW", which allows bots to crawl the paths on the page without adding the page to the search index.
In a pinch, you can block the sort parameters in Google Webmaster Tools, like I've described above.
DO IT NOW! Search for internal duplicates and get rid of them if there are any.
Hope this will help you avoid most of the bottlenecks, related to duplicate content. If not, I'm always available and ready to help! Just send me a note:)
We're now almost done, testing our website for Search Engine–friendliness. Just a couple of small points coming. So let's go further!

Answer
Answer
Answer
Answer
Answer
Answer
Answer
Answer
Answer
Answer